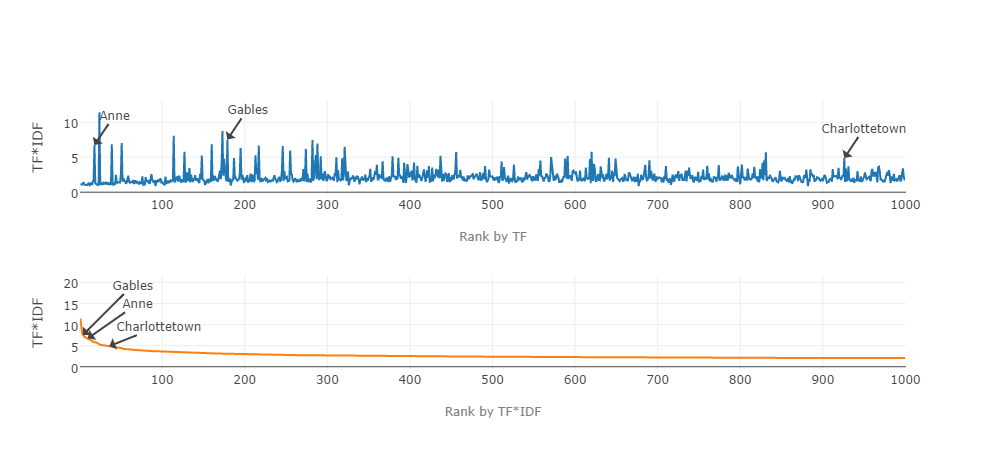
A Dataset of Term Stats in Literature
Following up on Term Weighting for Humanists, I’m sharing data and code to apply term weighting to literature in the HTRC’s Extracted Features dataset.
Prepared from 235,000 Language and Literature (i.e. LCC Class P) volumes, I’ve…